|
I am a joint Postdoc researcher in Beihang University (2025.11-) under the supervision of Prof. Weifeng Lv and Prof. Xianglong Liu and the Chinese University of Hong Kong (2026.02-) under the supervision of Prof. Qi Dou. Previously, I am a Ph.D. student (2021.09-) at the State Key Laboratory of Critical and Complex Development Environment (SKLCCDE) at Beihang University, Beijing, China, supervised by Prof. Xianglong Liu. I also receive supervision from Prof. Yaodong Yang at Peking University (2023.03-). I am a visiting scholar (2024.06 - 2025.05) at Nanyang Technological University (NTU), under the supervision of Prof. Bo An. Before that, I obtained my BSc degree in 2020 from Beihang University (Summa Cum Laude). [Prospective students] Our group has positions for PhD students, Master students, and visiting students. If you are interested, please send me an email with your CV and publications (if any). [Companies] I am open to cooperation. I am particularly interested in research on single/multi-agent VLA/LLM and their robustness. I am also interested in AI alignment and deception. Please send me an email for contact.Email: lisiminsimon@buaa.edu.cn |
 |
|
I work on Robust for multi-agent reinforcement learning (MARL) during my PhD. My research goal is to make reinforcement learning safe and robust, including practical adversarial attack for RL/MARL, robustness evaluation of MARL and adversarial defense. new I currently working on Robust Multi-Agent VLA/LLMs and AI Alignment. Now my research mainly includes:
|
|
[2026.01] Five papers (one first-authored, one corresponding) submitted to ICML 2026 [2025.06] One corresponding paper on robust VLA accepted by ICLR 2026 [2025.06] One first-authored paper on MARL attack accepted by Neural Networks [2025.06] One first-authored paper on robust MARL accepted by IEEE TNNLS [2025.05] One co-first-authored paper on robust financial trading accepted by KDD [2024.06] One first-authored paper submitted to IEEE TPAMI [2024.02] One co-authored paper on collision avoidance accepted by IEEE RAL [2024.01] One first-authored paper on defending Byzantine adversary of MARL accepted by ICLR 2024 [2024.01] One co-authored paper on partial symmetry for MARL accepted by AAAI 2024 [2022.11] One first-authored paper on naturalness of physical world adversarial attack accepted by CVPR 2023 [2022.07] One first-authored paper on privacy protection of fingerprints accepted by IEEE TIP. [2022.04] One co-authored paper on robustness testing of MARL accepted by CVPR 2022 workshop. |
|
|
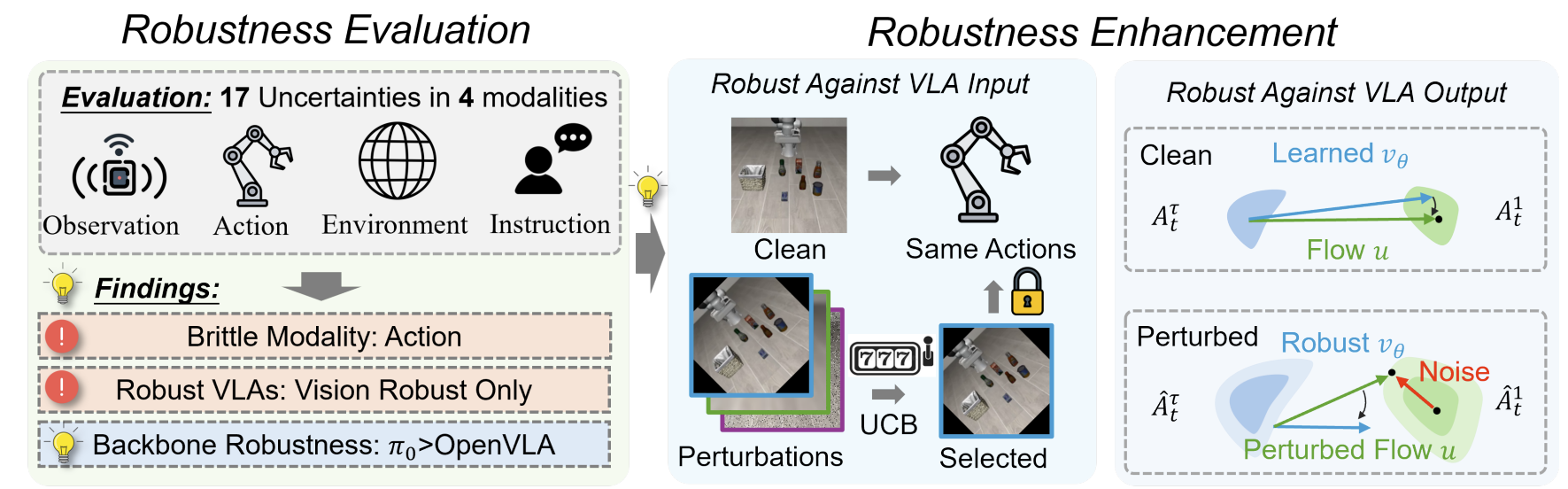 |
We derive adversarial training methods to achieve robust VLAs against perturbations in multi modalities. |
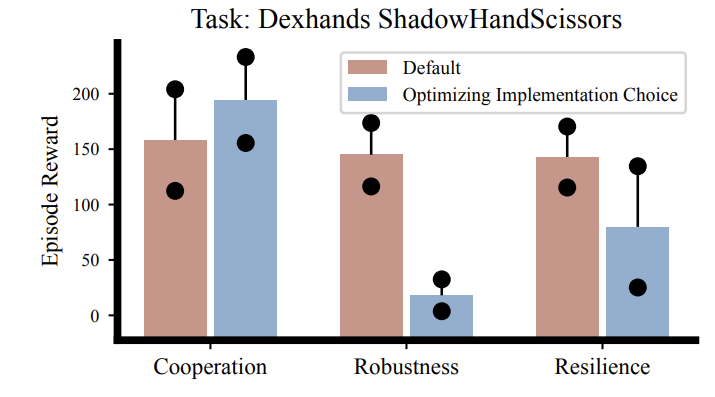 |
We provide a comprehensive evaluation to throughly study the effect of robustness and resilience in MARL. |
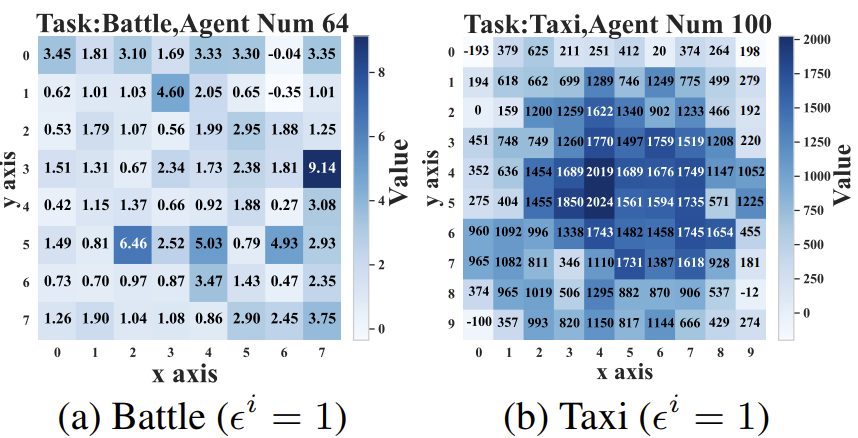 |
We design a principled method to identify vulnerable agents in large-scale multi-agent systems. |
 |
We propose a transferable adversarial policy framework for mixed cooperative-competitive games. |
 |
We develop theories on Maximum Entropy Heterogeneous-Agent RL, which is principally the optimal way of MARL learning. We proof it is robust to attacks in state, action, reward and environment transitions. Our algorithm outperforms strong baselines in 34 out of 38 tasks, and is robust to perturbations with different modalities across 14 magnitudes. |
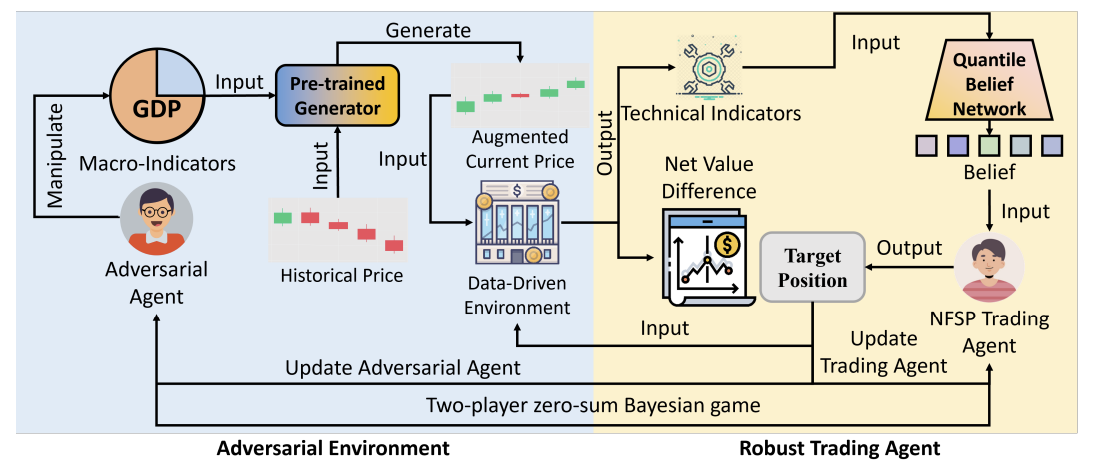 |
We use Bayesian robust RL techniques for robust financial trading. |
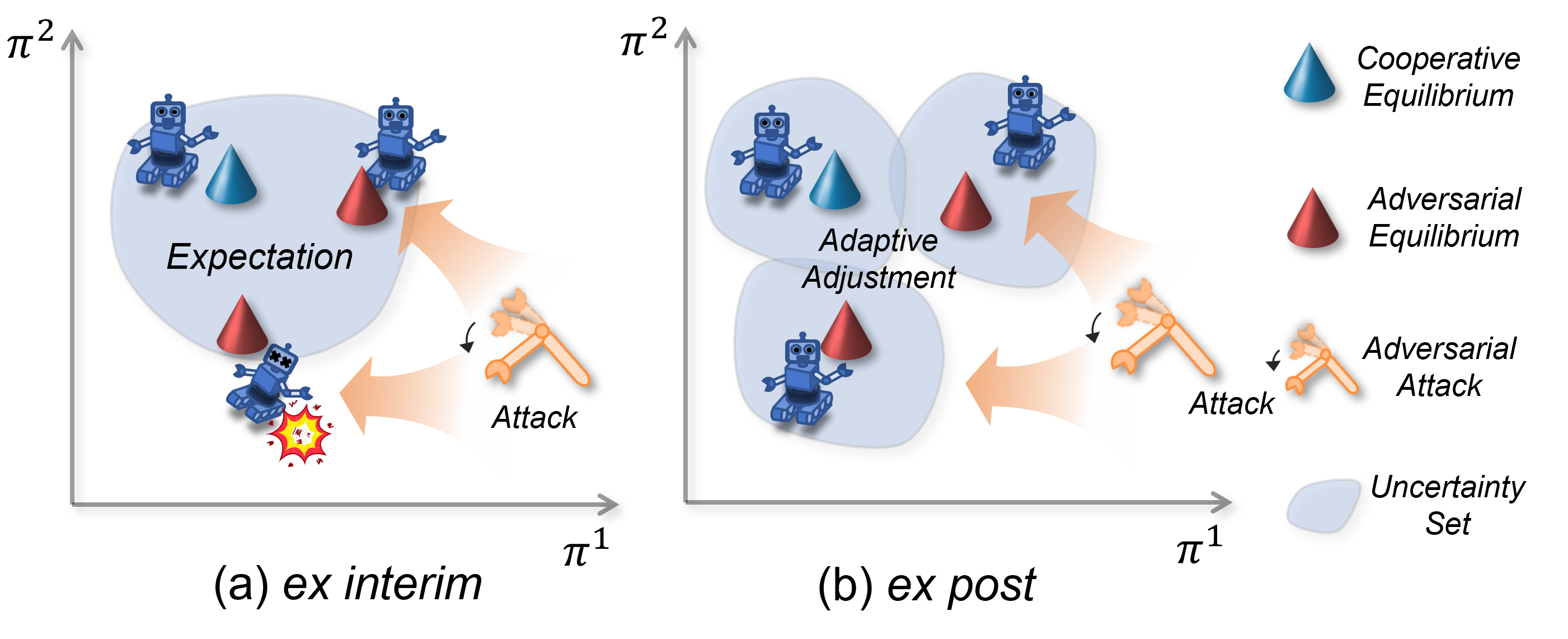 |
We study robustness of MARL against Byzantine action perturbations by formulating it as a Bayesian game. We provide a rigorious formulation of this problem and an algorithm with strong empirical performance. |
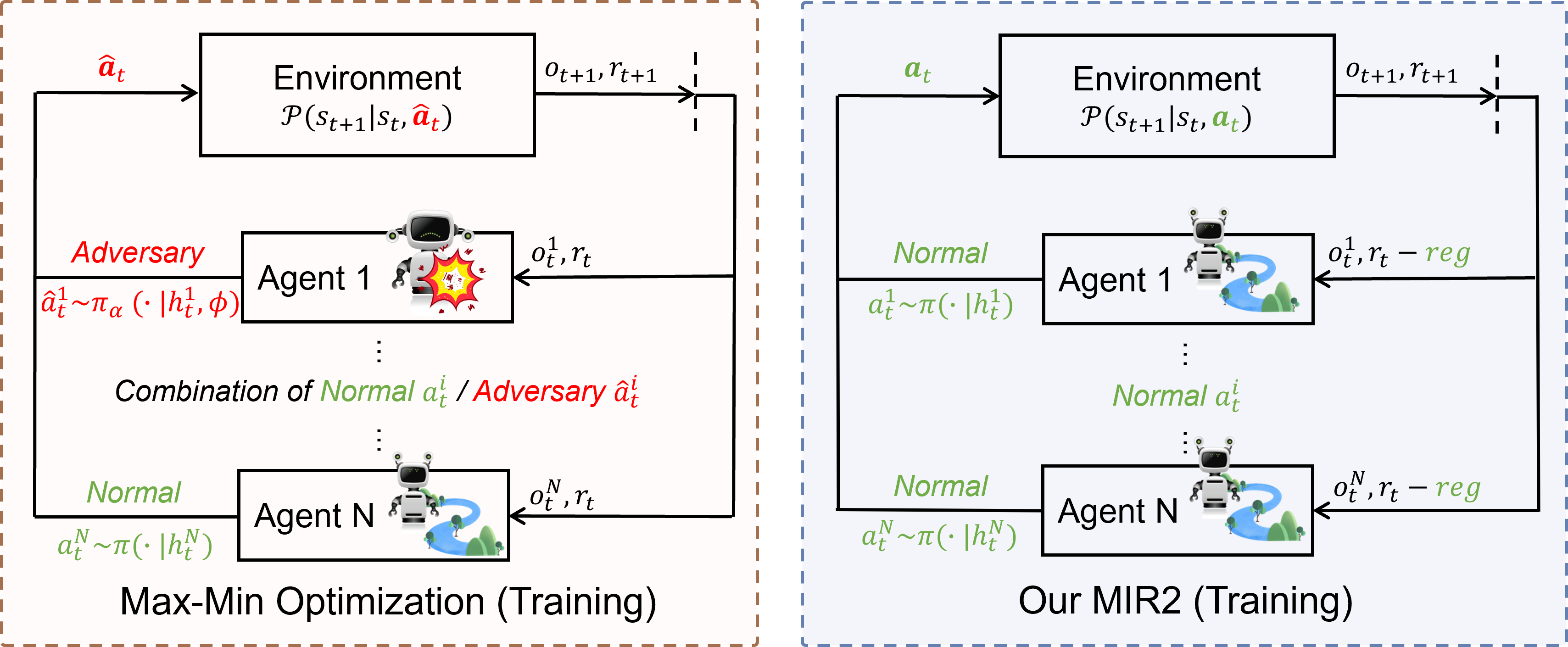 |
We proof that minimizing mutual information as a regularization term is minimizing a lower bound of robustness in MARL under all potential threat scenarios. |
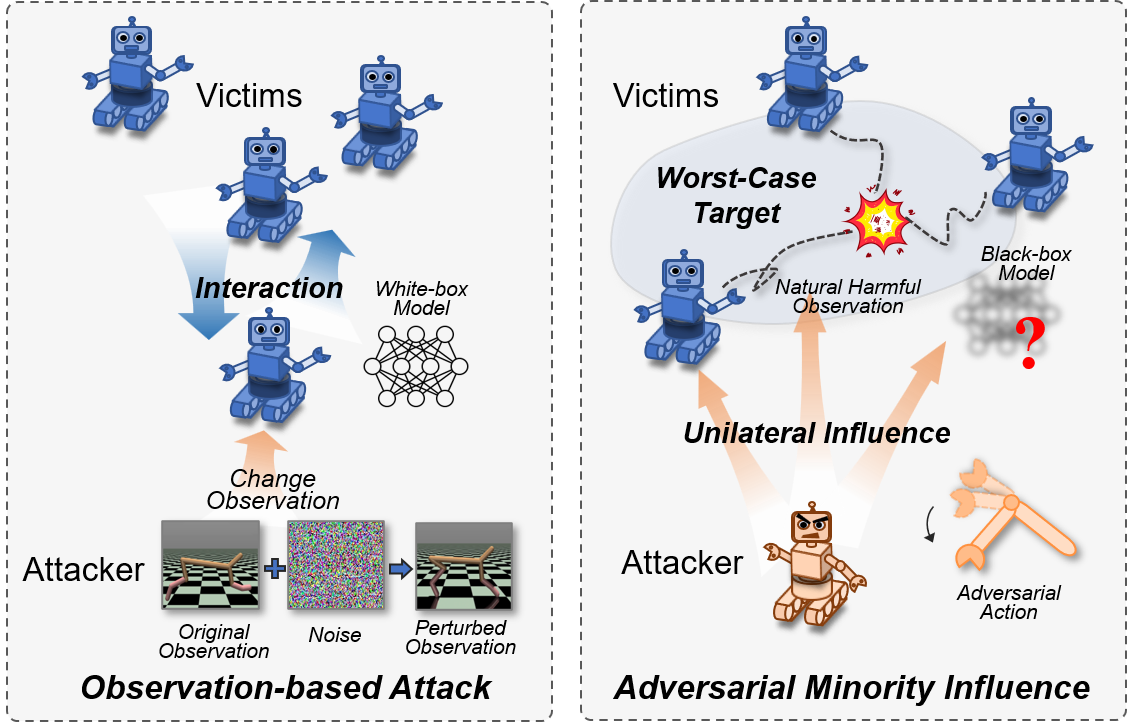 |
We propose the first adversarial policy attack for c-MARL, which is strong and practical. Our attack provides the first demonstration that adversarial policy is effective against real world robot swarms. |
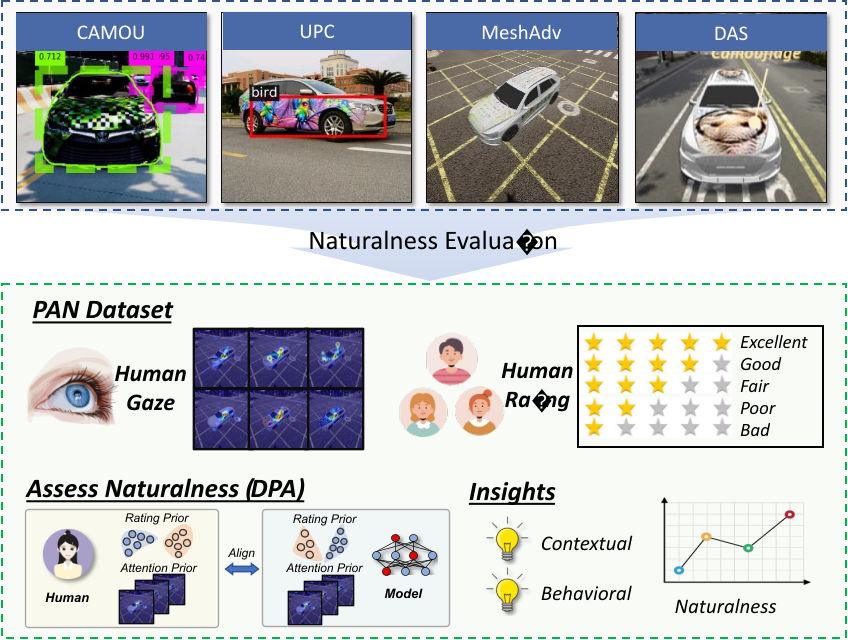 |
Simin Li, Shuning Zhang, Gujun Chen, Dong Wang, Pu Feng, Jiakai Wang, Aishan Liu, Xin Yi, Xianglong Liu. Accepted by CVPR, 2023 pdf / Project page We take the first step to evaluate the naturalness of physical world adversarial examples by a human oriented approach. We collect the first dataset with human naturalness ratings and human gaze, unveil insights of how contextual and behavioral features will affect attack naturalness, and propose an algorithm to automatically evaluate naturalness by aligning human behavior and algorithm prediction. |
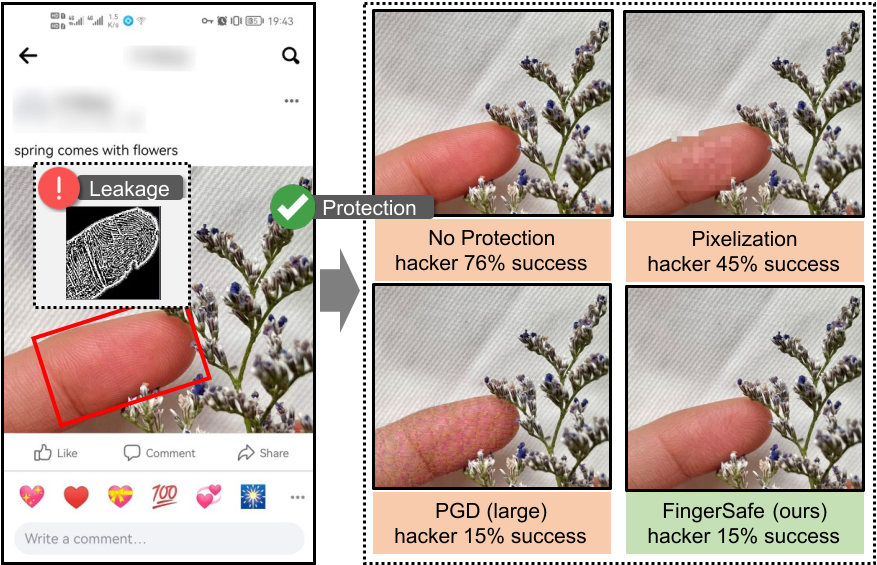 |
While billions of people are sharing their daily life images on social media everyday, hackers can easily steal fingerprint from the shared images. We leverage adversarial attack to protect such privacy leakage, such that hackers cannot extract fingerprints even they get the shared images in social media. Our method, FingerSafe, is strong for protection and natural for daily use. |
 |
We propose a testing framework to evaluate the robustness of multi-agent reinforcement learning (MARL) algoritms from the aspect of observation, action and reward. Our work first point out state-of-the-art MARL algorithms, including QMIX and MAPPO, are non-robust in multiple aspects, and point out the urgent need to test and enhance the robustness of MARL algorithms. |
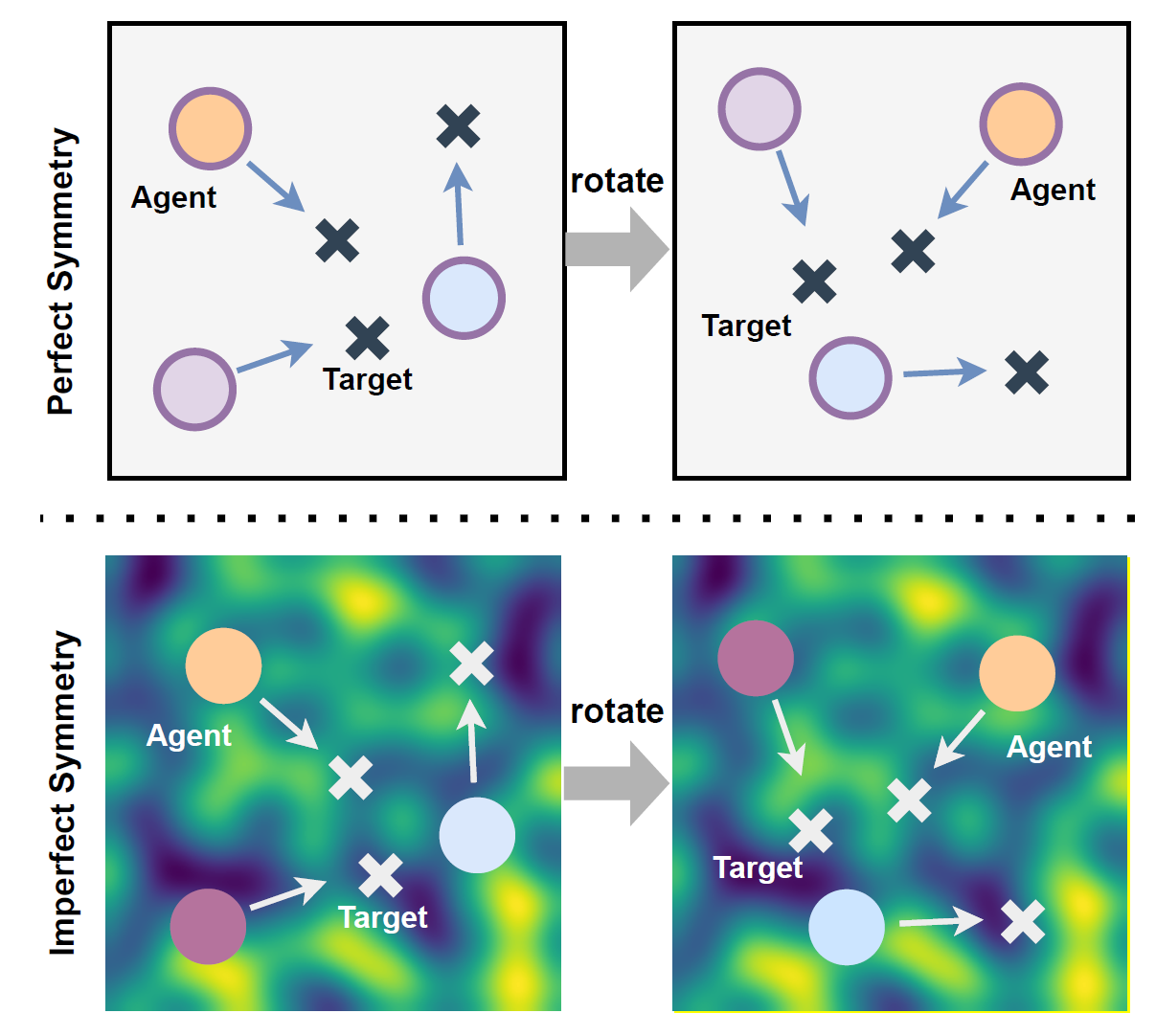 |
Symmetry has been used in MARL as a prior to incorporate domain knowledge in the environment, which enhance sample efficiency and performance. In this paper, we extend symmetry to paritial symmetry that considers uncertainties in environment with non-uniform field, including uneven terrain, wind, etc. |
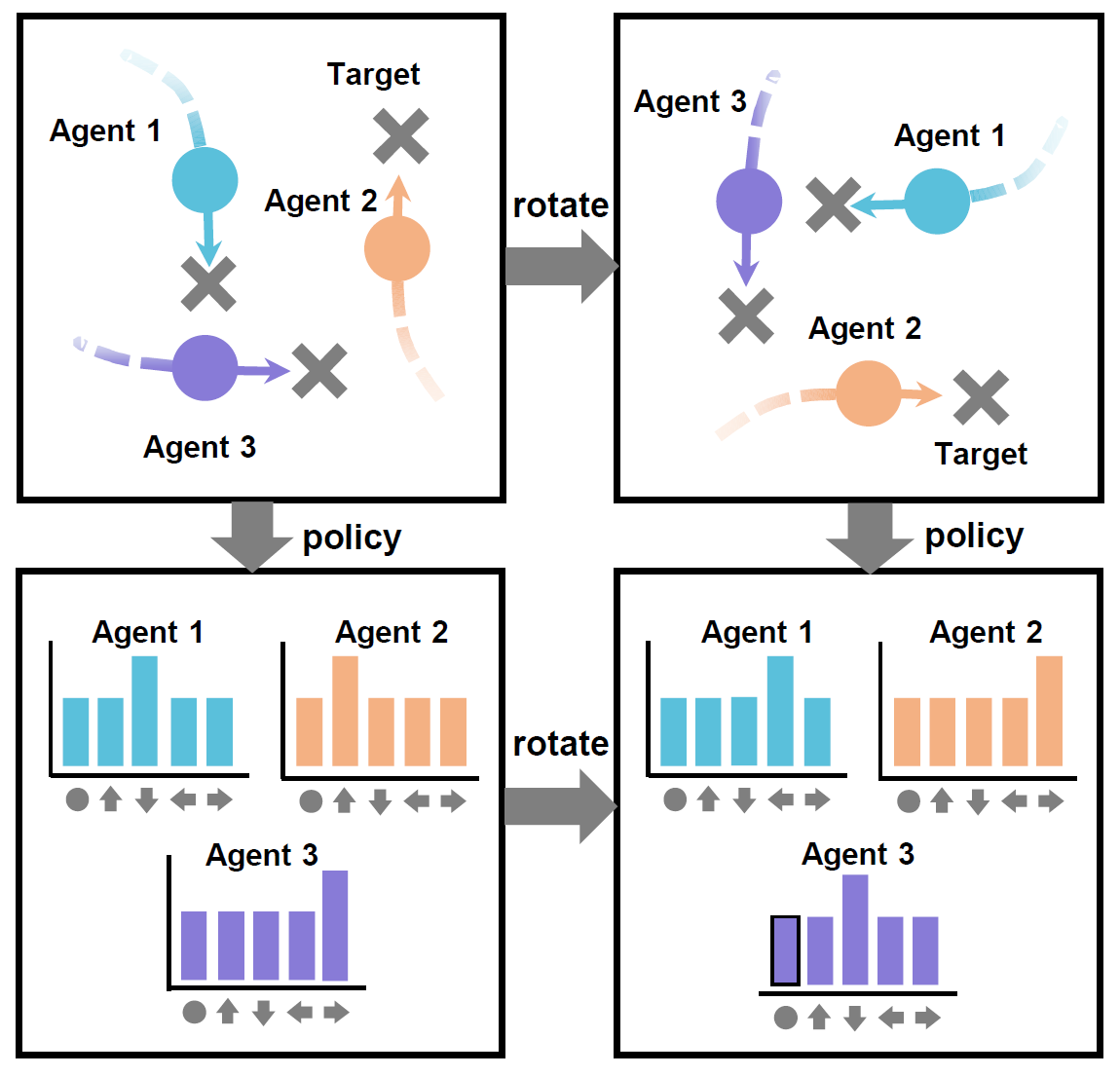 |
Symmetry are everywhere in real world, yet current MARL algorithms are agnostic of such symmetry by design. We extend the idea of symmetry to temporal domain, proposing spatial-temporal symmetry network, which includes adds a stronger induction bias during network training. |
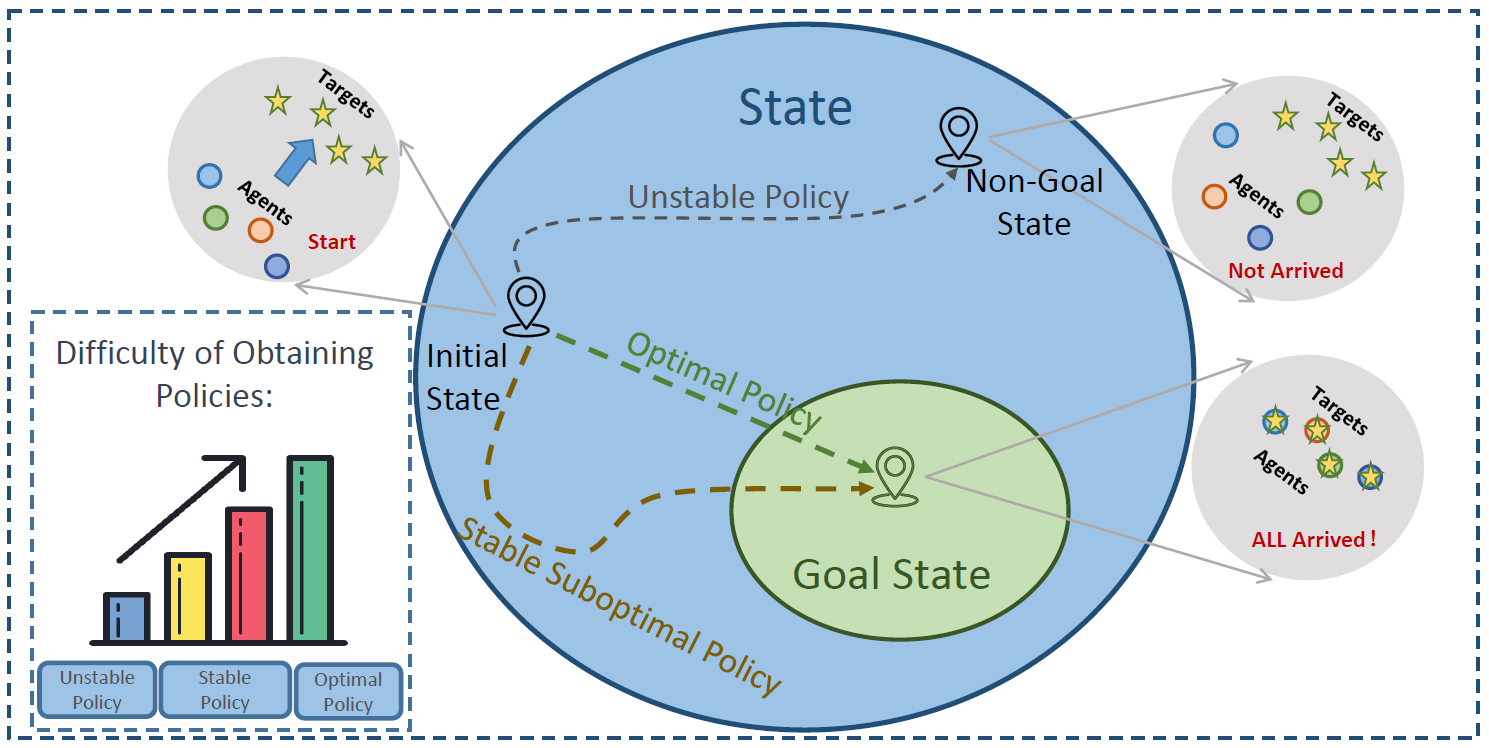 |
Many MARL tasks specify certain goal states where special rewards are granted. The optimal policy in such task could be characterized by Lyapnov stability, where the policy asymptotically converge to the goal states from any initial, making the goal states stable equilibria. We formulate such process as a Lyapunov Markov game, and proof it facilitates the training process to find a stable suboptimal policy more easily and then converge to an optimal policy more efficiently. |
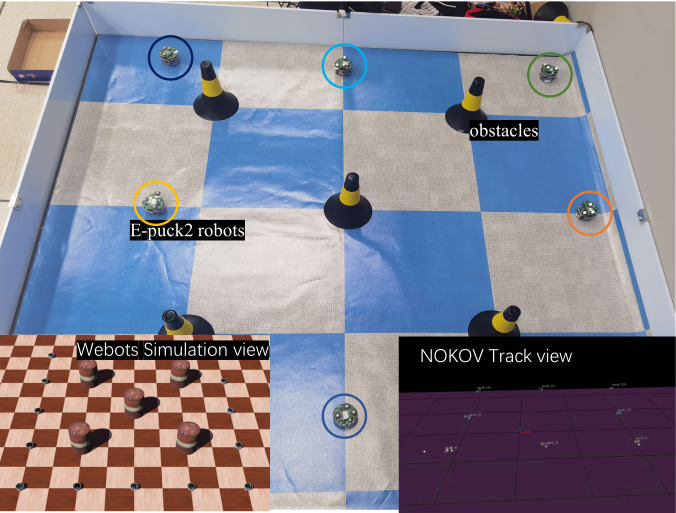 |
Pu Feng, Xin Yu, Wenjun Wu, Yongkai Tian, Junkang Liang, Simin Li. Submitted to RAL, 2024. Motivated by soft potential field theory, we propose an algorithm to avoid collision in robot swarms. |
 |
Aishan Liu, Jun Guo, Simin Li, Yisong Xiao, Xianglong Liu, Dacheng Tao. Accepted by Chinese Journal of Computers (计算机学报, top journal in China, CCF-A), 2023. We provide a comprehensive survey of attack and defenses for deep reinforcement learning. We first analyze adversarial attacks from the perspectives of state-based, reward-based and action based attacks. Then, we illustrate adversarial defenses from adversarial training, adversarial detection, certified robustness and robust learning. Finally, we investigate interesting topics including adversaries for good and model robustness understanding for DRL, and highlights open issues and future challenges in this field. |
|
Shuangcheng Liu, Simin Li (corresponding author), Hainan Li, Jingqiao Xiu, Aishan Liu, Xianglong Liu. Accepted by Journal of Cybersecurity (网络空间安全科学学报, Chinese journal on AI secuity), 2023. We provide an AirSim-based unmanned aerial vehicle (UAV) simulator. Based on this simulator, we identify several critical adversarial attacks in multi-UAV combat. |
|
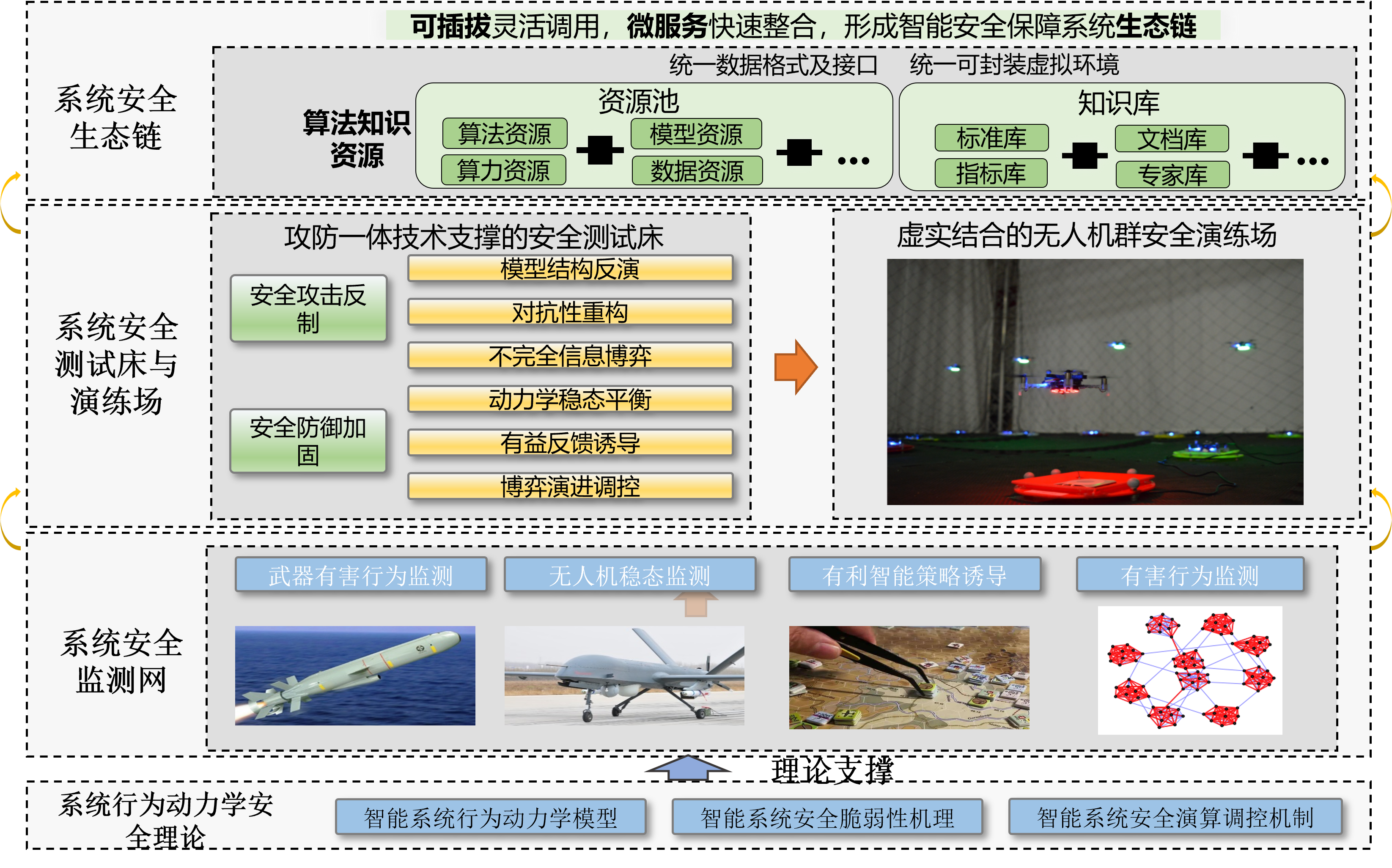 |
Simin Li, Jiakai Wang, Aishan Liu, Xianglong Liu. Accepted by Journal of Cybersecurity (网络空间安全科学学报, Chinese journal on AI secuity), 2023. We advocate the research on behavioral dynamics, which provides both microscopic and macroscopic understanding on adversarial vulnerability. We argue that combining the search of network science and game theory with AI safety could potentially benefit the understanding on micro information transmission and macro agent-wise intereaction. |
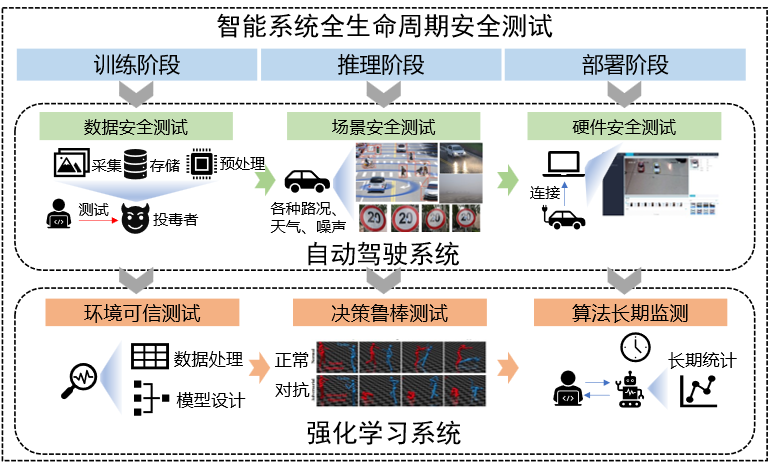 |
Jiakai Wang, Aishan Liu, Simin Li, Xianglong Liu, Wenjun Wu. Accepted by Artificial Intelligence Security (智能安全, Chinese journal on AI secuity), 2023. We propose our recent insight to test the security of an intelligent system from full life cycles, including vulnerabilities in model training, testing and deployment and their testing techniques. We offer insights on safety standards, safety testing platforms and sketch our method on security evaluation of autonomous driving. |
|
Joint Postdoc Program (国家级博士后派出计划), 2026. Excellent Doctoral Dissertation Award of Beihang University (北航优秀博士生学位论文), 2026. Youth Talent Support Program of the China Association for Science and Technology for Doctoral Students (中国科协青年人才托举工程博士生专项计划), 2024. National Scholarship, 2024. State-Sponsored Scholarship for joint PhD students, 2024 (120K RMB). Doctoral Research Excellence Academic Fund, 2024 (40K RMB). |
|
[Workshop@CVPR]I serve as Program Commitee at workshop The Art of Robustness: Devil and Angel in Adversarial Machine Learning at CVPR 2023. [Reviewer]I am a reviewer of ICLR, ICML, NeurIPS, etc. and area chair of DAI. |